Ngôn Ngữ, Xác Suất và Nhận Thức – phương trình công nghệ trong lịch sử mô hình hóa ngôn ngữ của nhân loại
Khám phá hành trình tiến hóa vĩ đại của mô hình ngôn ngữ, nơi ngôn ngữ, xác suất và nhận thức đan xen trong suốt tiến trình lịch sử công nghệ: từ những mô hình thống kê N-gram giản đơn, đến mạng nơ-ron và RNN, rồi bứt phá với LSTM, Seq2Seq và Attention; từ cuộc cách mạng Transformer mở đường cho BERT, GPT và vô số biến thể, đến kỷ nguyên LLM với khả năng sáng tạo, suy luận, đa phương thức. Đây không chỉ là câu chuyện kỹ thuật, mà còn là bản trường ca triết học về cách máy móc phản chiếu tư duy con người và gợi mở viễn cảnh trí tuệ nhân tạo tổng quát.

Ngôn ngữ không chỉ là phương tiện giao tiếp, nó là viên gạch đầu tiên, là chất keo kết dính, là dòng chảy không ngừng nghỉ định hình nên trí tuệ và văn minh nhân loại. Từ thuở sơ khai, khả năng diễn đạt, ghi nhớ và truyền thụ tri thức qua ngôn ngữ đã tách biệt con người khỏi mọi sinh vật khác, cho phép chúng ta xây dựng nền văn hóa, khoa học và xã hội phức tạp.
1. Tiếng Nói Của Trí Tuệ – Vì sao loài người cần máy biết hiểu và biết nói?
Khi chúng ta bước vào kỷ nguyên số – một kỷ nguyên mà thông tin bùng nổ và máy tính trở thành cánh tay nối dài của trí óc – một câu hỏi mang tính nền tảng và đầy thách thức đã nảy sinh:
-> Làm thế nào để máy tính, một cỗ máy logic thuần túy, có thể thấu hiểu, diễn giải, và thậm chí tự mình sản sinh ra thứ ngôn ngữ tự nhiên, đầy sắc thái và biến ảo của con người?
Đây không chỉ là một vấn đề kỹ thuật, đó là một khát vọng sâu xa về việc mở rộng khả năng của con người thông qua công nghệ. Chính từ khát vọng đó, khái niệm Mô hình Ngôn ngữ (Language Model – LM) đã ra đời. Ở cốt lõi, LM là một hệ thống toán học hoặc máy học được thiết kế để ước lượng xác suất của một chuỗi từ (ví dụ: một câu, một đoạn văn), hoặc dự đoán từ có khả năng xuất hiện tiếp theo trong một ngữ cảnh cho trước.
Tại sao chúng ta cần xác suất này? Vì việc hiểu ngôn ngữ thường quy về việc dự đoán điều gì có khả năng xảy ra nhất. Ví dụ:
- Trong dịch máy, ta cần tìm chuỗi từ tiếng đích có xác suất cao nhất tương ứng với tiếng nguồn.
- Trong nhận dạng giọng nói, ta cần xác định chuỗi từ có xác suất cao nhất khớp với âm thanh đã nghe.
- Trong gõ dự đoán, ta muốn máy gợi ý từ tiếp theo phù hợp nhất.
- Trong tìm kiếm thông tin, ta muốn hệ thống hiểu ý định truy vấn để trả về kết quả liên quan nhất.
Mỗi bước tiến trong hành trình của LM không chỉ là một đổi mới công nghệ, mà là một nỗ lực vượt qua những giới hạn cố hữu, mở ra những chân trời mới cho sự tương tác giữa con người và máy tính.
2. Thời kỳ thống kê: N-gram – Nền móng sơ khai từ ngôn ngữ rời rạc (Thập niên 1980 – 2000)
2.1. Động lực: Thức thời và thực dụng
Vào những năm 1980 và 1990, tài nguyên tính toán còn rất hạn chế. Các nhà nghiên cứu Xử lý Ngôn ngữ Tự nhiên (NLP) đã chọn một con đường thực dụng và hiệu quả: thống kê. Ý tưởng trung tâm là ngôn ngữ, dù phức tạp, vẫn có thể được mô hình hóa thông qua các quy luật xác suất ẩn trong các tập dữ liệu lớn. Nếu chúng ta đếm được tần suất các từ và chuỗi từ xuất hiện cùng nhau, chúng ta có thể "dự đoán" hành vi của ngôn ngữ.
Bài toán ban đầu là làm sao để ước lượng , tức xác suất của một chuỗi từ. Việc này rất khó vì không gian các chuỗi từ là vô hạn. Giải pháp là áp dụng giả định Markov, cho rằng xác suất của một từ chỉ phụ thuộc vào một số ít từ đứng ngay trước nó.
2.2. N-gram Model: Sức mạnh của sự đơn giản
Với giả định Markov, công thức xác suất chuỗi từ được xấp xỉ bằng tích các xác suất có điều kiện:
Trong đó:
-
: từ thứ trong chuỗi.
-
: độ dài của chuỗi từ.
-
: số lượng từ trong ngữ cảnh (cửa sổ n-gram).
-
: xác suất từ xảy ra khi biết trước từ ngay trước nó.
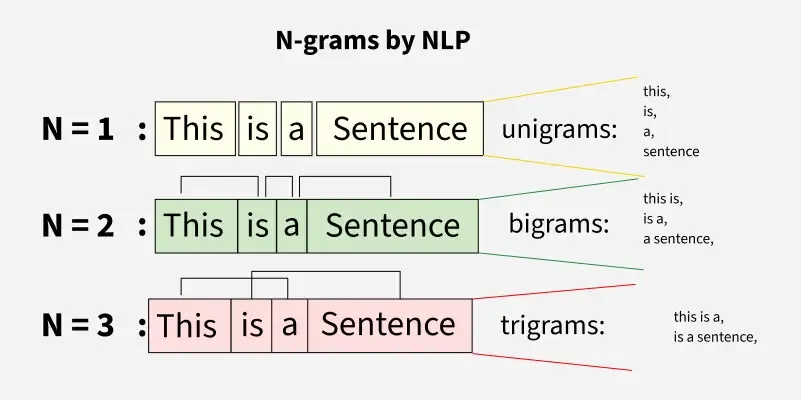
Minh họa N-gram: từ Unigram đến Trigram trong mô hình xác suất ngôn ngữ.
Ở đây, **N** chính là số lượng từ trong ngữ cảnh mà chúng ta xét để dự đoán từ tiếp theo.- Unigram (N=1): – Coi mỗi từ độc lập, bỏ qua ngữ cảnh hoàn toàn. (Rất đơn giản, ít ý nghĩa)
- Bigram (N=2): – Xác suất của từ chỉ phụ thuộc vào từ ngay trước đó.
- Trigram (N=3): – Xác suất của từ phụ thuộc vào hai từ trước đó.
Ví dụ: Để dự đoán từ tiếp theo trong "Tôi ăn cơm bằng...", một mô hình Bigram sẽ chỉ tập trung vào từ "bằng" để đưa ra dự đoán (ví dụ: "đũa", "muỗng"). Một mô hình Trigram sẽ nhìn vào "cơm bằng" để đưa ra dự đoán chính xác hơn.
Các xác suất được ước lượng bằng cách đếm tần suất xuất hiện các n-gram trong một tập dữ liệu huấn luyện lớn.
2.3. Ưu và nhược điểm: Giới hạn của tầm nhìn ngắn hạn
Ưu điểm:
- Đơn giản, dễ triển khai: Yêu cầu ít tài nguyên tính toán và kiến thức chuyên sâu.
- Hiệu quả bất ngờ: Đủ tốt cho nhiều ứng dụng ban đầu như nhận dạng giọng nói hoặc đánh vần, nơi ngữ cảnh cục bộ là đủ.
- Dễ diễn giải: Ta có thể dễ dàng thấy xác suất của từng cặp hoặc bộ ba từ.
Nhược điểm và những vấn đề thúc đẩy sự thay đổi:
- Ngữ cảnh ngắn và cục bộ: N-gram bị "cận thị" nghiêm trọng. Chúng không thể nắm bắt được các mối quan hệ ngữ nghĩa hoặc cú pháp dài hơn vài từ. Ví dụ, trong câu "Con mèo mà nằm trên chiếu, nó bắt được con chuột chạy qua bếp", một Trigram không thể hiểu mối quan hệ giữa "mèo" và "nó" ở xa nhau.
- Vấn đề từ thưa (Sparsity Problem): Khi N tăng, số lượng n-gram tiềm năng bùng nổ theo cấp số nhân. Nhiều n-gram hợp lệ trong ngôn ngữ tự nhiên có thể không bao giờ xuất hiện trong tập huấn luyện (zero-frequency problem). Điều này dẫn đến xác suất bằng 0, làm mô hình không thể đưa ra dự đoán. Các kỹ thuật làm mịn (smoothing) như Laplace smoothing hay Kneser-Ney đã được phát triển nhưng chỉ là giải pháp tạm thời.
- Kích thước từ điển bùng nổ: Mỗi từ được coi là một ký hiệu riêng biệt, không có mối quan hệ ngữ nghĩa nào với các từ khác. "Ô tô" và "xe hơi" được coi là hai thực thể hoàn toàn khác nhau.
- Không học được ngữ nghĩa ẩn: N-gram chỉ đếm. Chúng không có khả năng học được ý nghĩa sâu sắc hay mối liên hệ trừu tượng giữa các từ.
Những hạn chế này đã tạo ra một nhu cầu cấp bách: cần một cách mô hình hóa ngôn ngữ linh hoạt hơn, có khả năng nắm bắt ngữ cảnh dài hơn và hiểu được ý nghĩa ẩn đằng sau các từ.
3. Neural Language Models – Làn sóng đầu tiên của học sâu trong ngôn ngữ (Đầu những năm 2000)
3.1. Động lực: Chuyển từ ký hiệu rời rạc sang số hóa ý nghĩa
N-gram coi mỗi từ như một ký hiệu độc lập, không liên quan đến nhau. Nhưng bộ não con người không hoạt động như vậy. Chúng ta hiểu rằng "ô tô" và "xe hơi" gần nghĩa, "vua" có mối quan hệ với "hoàng hậu" tương tự như "đàn ông" với "phụ nữ". Điều này có nghĩa là các từ có thể tồn tại trong một không gian ngữ nghĩa, nơi khoảng cách giữa chúng thể hiện mức độ tương đồng về ý nghĩa.
Để máy tính có thể "hiểu" được các mối quan hệ này, cần một cách để biểu diễn từ ngữ trong một không gian liên tục, nơi các từ có ý nghĩa tương tự được đặt gần nhau về mặt toán học.
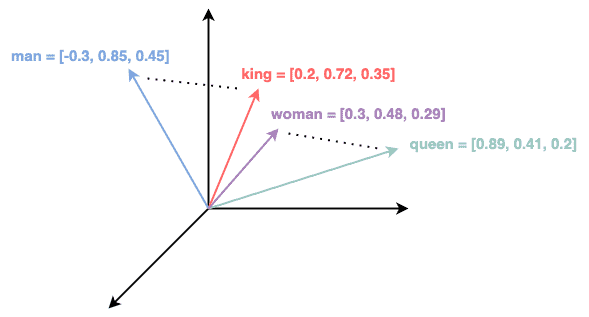
Không gian vector biểu diễn ý nghĩa các từ.
### 3.2. Mô hình đột phá của Bengio và cộng sự (2003)Yoshua Bengio cùng với Réjean Ducharme, Pascal Vincent và Christian Janvin đã công bố bài báo mang tính biểu tượng “A Neural Probabilistic Language Model” vào năm 2003. Đây không chỉ là một mô hình, mà là một tuyên ngôn, đặt nền móng cho toàn bộ kỷ nguyên học sâu trong NLP.
Điểm đột phá của họ:
- Word Embeddings (Biểu diễn Từ Nhúng): Thay vì sử dụng các ký hiệu rời rạc, mỗi từ được ánh xạ tới một vector dày đặc (dense vector) trong một không gian có số chiều thấp. Các giá trị trong vector này được học trong quá trình huấn luyện, cho phép từ có ý nghĩa tương tự có các vector gần nhau.
- Mạng Nơ-ron (MLP): Một mạng nơ-ron truyền thẳng (Multi-Layer Perceptron) được sử dụng để nhận các vector nhúng của các từ trong cửa sổ ngữ cảnh và dự đoán từ tiếp theo.
Ý nghĩa:
- Biểu diễn phân tán (Distributed Representation): Mỗi đặc trưng của từ (giới tính, thì, chủ đề...) không được mã hóa vào một chiều riêng biệt, mà phân tán trên toàn bộ các chiều của vector. Điều này giúp mô hình tổng quát hóa tốt hơn và xử lý các từ mới hiệu quả hơn.
- Hiểu ngữ nghĩa: Tự động học: Các embedding không được định nghĩa thủ công mà được mô hình tự động học từ dữ liệu.
"king" - "man" + "woman" ≈ "queen"là một ví dụ kinh điển về khả năng của embedding trong việc mã hóa các mối quan hệ ngữ nghĩa. - Khắc phục vấn đề thưa: Ngay cả khi một n-gram cụ thể không xuất hiện, nếu các từ thành phần của nó đã được học, mô hình vẫn có thể đưa ra dự đoán hợp lý dựa trên sự tương đồng ngữ nghĩa của các embedding.
3.3. Hạn chế và nhu cầu phát triển: cửa sổ cố định và chi phí tính toán
Mặc dù là một bước tiến vĩ đại, NNLM của Bengio vẫn còn tồn tại những giới hạn:
- Chỉ nhìn được cửa sổ ngữ cảnh cố định: Giống như N-gram, NNLM chỉ có thể xem xét một số lượng từ cố định trước đó để dự đoán từ tiếp theo. Điều này vẫn hạn chế khả năng nắm bắt các mối quan hệ ngữ pháp hoặc ngữ nghĩa dài hạn.
- Chi phí tính toán cao: Để dự đoán từ tiếp theo, mô hình cần tính toán xác suất cho tất cả các từ trong từ vựng, sau đó áp dụng hàm softmax. Với từ vựng hàng chục hoặc hàng trăm ngàn từ, đây là một phép toán rất đắt đỏ.
- Không nắm bắt được thứ tự linh hoạt: Dù có embedding, mô hình vẫn chưa thực sự hiểu được cấu trúc tuần tự của ngôn ngữ một cách tự nhiên.
Những hạn chế này đã thúc đẩy các nhà nghiên cứu tìm kiếm một kiến trúc có khả năng "ghi nhớ" thông tin từ quá khứ một cách linh hoạt, không giới hạn bởi cửa sổ cố định, và xử lý được các chuỗi dữ liệu dài một cách hiệu quả hơn.
4. Recurrent Neural Network (RNN): Bộ nhớ tuần tự (Thập niên 1990 – 2010)
4.1. Động lực: Phá vỡ xiềng xích ngữ cảnh cố định
Ngôn ngữ là một chuỗi tuần tự. Một từ ở đầu câu có thể ảnh hưởng đến ý nghĩa hoặc cấu trúc ngữ pháp ở cuối câu. NNLM, với cửa sổ ngữ cảnh cố định, không thể giải quyết triệt để vấn đề này. Các nhà nghiên cứu cần một kiến trúc cho phép thông tin từ các bước thời gian trước đó được "ghi nhớ" và "chuyển tiếp" sang các bước thời gian sau.
Ý tưởng nảy sinh: nếu một mạng nơ-ron có thể "nhắc lại" những gì nó đã thấy trước đó, nó có thể xử lý các chuỗi có độ dài bất kỳ một cách hiệu quả hơn.
4.2. Cách Hoạt Động: Vòng lặp trí nhớ
RNN giải quyết vấn đề này bằng cách thêm một vòng lặp (recurrent connection) vào kiến trúc của nó. Tại mỗi bước thời gian , RNN nhận đầu vào (ví dụ: embedding của từ hiện tại) và một trạng thái ẩn (hidden state) từ bước thời gian trước. Nó sử dụng cả hai để tạo ra trạng thái ẩn mới và (tùy chọn) một đầu ra .
Công thức cơ bản:
Trong đó:
- là một hàm phi tuyến tính (ví dụ: tanh, ReLU).
- là ma trận trọng số, là bias.
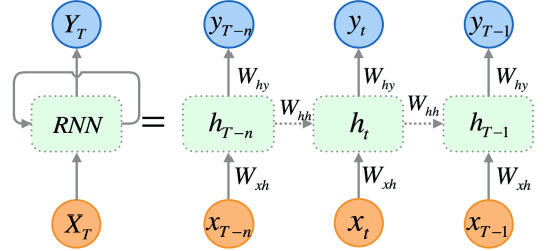
Kiến trúc RNN: đầu vào tuần tự và vòng lặp trạng thái ẩn giúp ghi nhớ quá khứ.
Cơ chế này cho phép thông tin từ các từ đầu chuỗi "lưu lại" trong trạng thái ẩn và ảnh hưởng đến việc xử lý các từ sau. Giống như việc con người ghi nhớ một phần cuộc trò chuyện để hiểu bối cảnh tiếp theo.4.3. Ưu và nhược điểm: Trí nhớ ngắn ngủi nà thách thức huấn luyện
Ưu điểm:
- Xử lý chuỗi độ dài bất kỳ: Khác với N-gram và NNLM, RNN có thể xử lý các câu dài mà không bị giới hạn bởi cửa sổ cố định.
- Học mối quan hệ tuần tự: Có khả năng nắm bắt các mối quan hệ ngữ cảnh giữa các từ cách xa nhau, ít nhất là về lý thuyết.
- Chia sẻ tham số: Các trọng số () được chia sẻ qua tất cả các bước thời gian, giúp mô hình học hiệu quả hơn.
Nhược điểm và Vấn đề Thúc Đẩy Đổi Mới:
- Vấn đề Vanishing/Exploding Gradient: Đây là "gót chân Achilles" của RNN. Khi gradient (đạo hàm) được lan truyền ngược qua nhiều bước thời gian trong quá trình huấn luyện (backpropagation through time), chúng có xu hướng hoặc trở nên quá nhỏ (vanishing gradient), khiến mạng không thể học được các mối quan hệ dài hạn, hoặc trở nên quá lớn (exploding gradient), làm cho quá trình huấn luyện không ổn định. Điều này khiến RNN thực tế vẫn khó học được các phụ thuộc xa.
- Không song song hóa được (Lack of Parallelism): Để tính toán , ta cần . Điều này có nghĩa là mỗi bước thời gian phải được xử lý tuần tự. Việc này làm cho quá trình huấn luyện và suy luận rất chậm, đặc biệt với các chuỗi dài, và không tận dụng được sức mạnh của các bộ xử lý song song như GPU.
- Thông tin bị nén quá mức: Trạng thái ẩn phải cố gắng gói gọn toàn bộ thông tin quan trọng từ quá khứ, điều này có thể trở thành một gánh nặng khi chuỗi quá dài.
Các vấn đề này, đặc biệt là khả năng học phụ thuộc dài hạn, đã thúc đẩy một thế hệ mô hình RNN mới mạnh mẽ hơn.
5. LSTM & GRU: Ký ức dài hạn với cổng kiểm soát (Cuối những năm 1990 – 2010)
5.1. Động lực: Cần một "Trí Nhớ" sắc sảo hơn
Nhận thấy vấn đề vanishing gradient của RNN cản trở việc học các phụ thuộc dài hạn, các nhà nghiên cứu đã đặt câu hỏi: Làm thế nào để RNN có thể "chọn lọc" thông tin nào cần ghi nhớ, thông tin nào cần quên, và thông tin nào cần truyền đi? Thay vì nén mọi thứ vào một trạng thái ẩn đơn thuần, cần một cơ chế tinh vi hơn để quản lý dòng chảy thông tin.
5.2. Long Short-Term Memory (LSTM) – 1997
Được giới thiệu bởi Sepp Hochreiter và Jürgen Schmidhuber vào năm 1997, LSTM là một kiến trúc đột phá, giải quyết hiệu quả vấn đề vanishing gradient. LSTM thêm vào các "cổng" (gates) và một trạng thái ô nhớ (cell state), hoạt động như một băng chuyền thông tin.
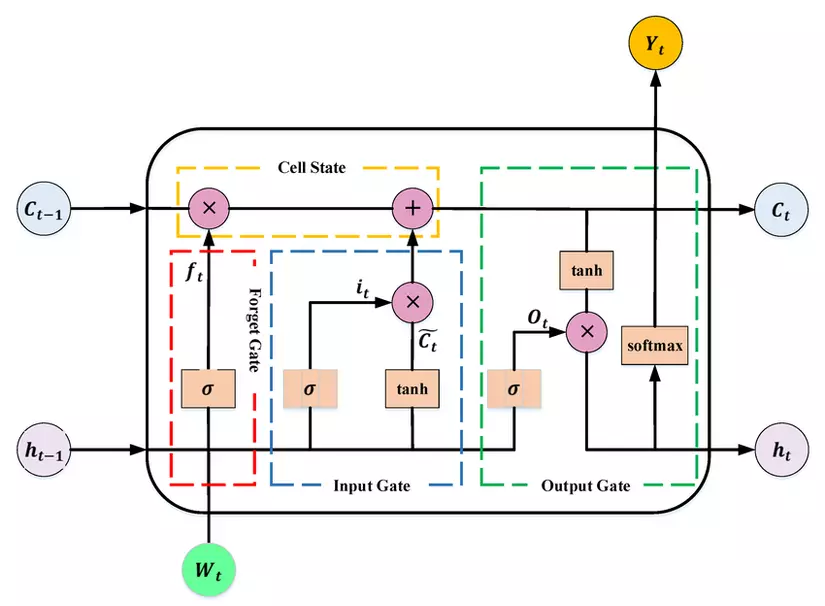
Sơ đồ chi tiết các cổng trong một tế bào LSTM: input, forget và output gate.
- **Cell State ($C_t$):** Là "bộ nhớ dài hạn", mang thông tin xuyên suốt chuỗi. - **Input Gate:** Quyết định thông tin mới nào từ đầu vào sẽ được thêm vào cell state. - **Forget Gate:** Quyết định thông tin nào trong cell state nên được "quên" đi. - **Output Gate:** Quyết định phần nào của cell state sẽ được "xuất ra" làm trạng thái ẩn $h_t$.Nhờ các cổng này, LSTM có thể giữ lại thông tin quan trọng trong thời gian rất dài mà không bị phai mờ, đồng thời bỏ qua thông tin không cần thiết.
5.3. Gated Recurrent Unit (GRU) – 2014
Được giới thiệu bởi Kyunghyun Cho và cộng sự vào năm 2014, GRU là một biến thể đơn giản hơn của LSTM. Nó hợp nhất forget gate và input gate thành một update gate và không có separate cell state.
- Update Gate: Quyết định mức độ thông tin từ trạng thái trước đó cần được giữ lại và mức độ thông tin mới từ đầu vào cần được thêm vào.
- Reset Gate: Quyết định bao nhiêu thông tin từ trạng thái trước đó nên được "quên" để chuẩn bị nhận thông tin mới.
Ưu điểm:
- Khả năng học phụ thuộc dài hạn vượt trội: LSTM và GRU đã giải quyết phần lớn vấn đề vanishing gradient, cho phép mô hình học được các mối quan hệ giữa các từ cách xa nhau trong câu hoặc đoạn văn.
- Hiệu quả thực tế: Trở thành xương sống cho nhiều hệ thống NLP hiện đại, từ dịch máy đến nhận dạng giọng nói, giúp chúng đạt được những kết quả chưa từng có.
- GRU đơn giản và nhanh hơn: Với ít tham số hơn, GRU thường hội tụ nhanh hơn và yêu cầu ít tài nguyên tính toán hơn một chút so với LSTM, trong khi vẫn duy trì hiệu suất tương đương trong nhiều tác vụ.
Nhược điểm và Giới Hạn Hiện Tại:
- Vẫn phải xử lý tuần tự: Dù mạnh mẽ hơn, cả LSTM và GRU vẫn kế thừa hạn chế cố hữu của RNN: chúng phải xử lý từng bước thời gian một cách tuần tự. Điều này vẫn cản trở khả năng song song hóa và làm chậm quá trình huấn luyện trên các tập dữ liệu lớn và chuỗi dài.
- Khó mở rộng cho chuỗi cực dài: Mặc dù tốt hơn RNN thuần túy, việc giữ thông tin liên tục qua hàng trăm hoặc hàng nghìn bước vẫn là một thách thức, đặc biệt là khi phải truyền qua nhiều lớp mạng.
- "Nút cổ chai thông tin" (bottleneck) cho các bài toán phức tạp: Khi cần biến đổi một chuỗi input thành một chuỗi output (ví dụ: dịch máy), toàn bộ thông tin của chuỗi input phải được nén vào một vector trạng thái ẩn cuối cùng. Điều này dễ gây mất mát thông tin với các chuỗi dài.
Những hạn chế này đã thúc đẩy sự ra đời của một kiến trúc mới, được thiết kế đặc biệt để xử lý các bài toán chuyển đổi chuỗi và mở khóa khả năng song song hóa triệt để.
6. Seq2Seq: Bước đột phá trong dịch máy và chuyển đổi chuỗi (Đầu những năm 2010)
6.1. Động lực: Biến một chuỗi thành chuỗi khác
Cho đến lúc này, các mô hình ngôn ngữ chủ yếu tập trung vào việc dự đoán từ tiếp theo hoặc phân loại một chuỗi. Tuy nhiên, nhiều ứng dụng thực tế đòi hỏi một khả năng phức tạp hơn: biến đổi một chuỗi đầu vào (input sequence) thành một chuỗi đầu ra (output sequence) khác. Dịch máy là ví dụ điển hình: chuyển một câu tiếng Anh thành một câu tiếng Việt. Các tác vụ như tóm tắt văn bản, sinh câu trả lời trong hội thoại cũng thuộc loại này.
RNN/LSTM đơn lẻ không thể trực tiếp làm điều này một cách hiệu quả vì độ dài của input và output thường khác nhau.
6.2. Kiến trúc Encoder-Decoder
Để giải quyết bài toán này, kiến trúc Seq2Seq (Sequence-to-Sequence) đã ra đời, thường sử dụng hai mạng RNN/LSTM/GRU riêng biệt:
- Encoder (Bộ Mã Hóa): Là một RNN/LSTM/GRU đọc toàn bộ chuỗi đầu vào (ví dụ: câu tiếng Anh), xử lý từng từ một và nén toàn bộ thông tin ngữ nghĩa và cú pháp của câu vào một vector ngữ cảnh (context vector) cố định ở bước cuối cùng. Vector này được coi là "ý nghĩa" của câu input.
- Decoder (Bộ Giải Mã): Là một RNN/LSTM/GRU khác. Nó nhận vector ngữ cảnh từ Encoder làm trạng thái khởi tạo, và sau đó sinh ra chuỗi đầu ra (ví dụ: câu tiếng Việt) từng từ một. Tại mỗi bước sinh, Decoder cũng nhận từ vừa sinh ra (hoặc từ tham chiếu) làm đầu vào để dự đoán từ tiếp theo.
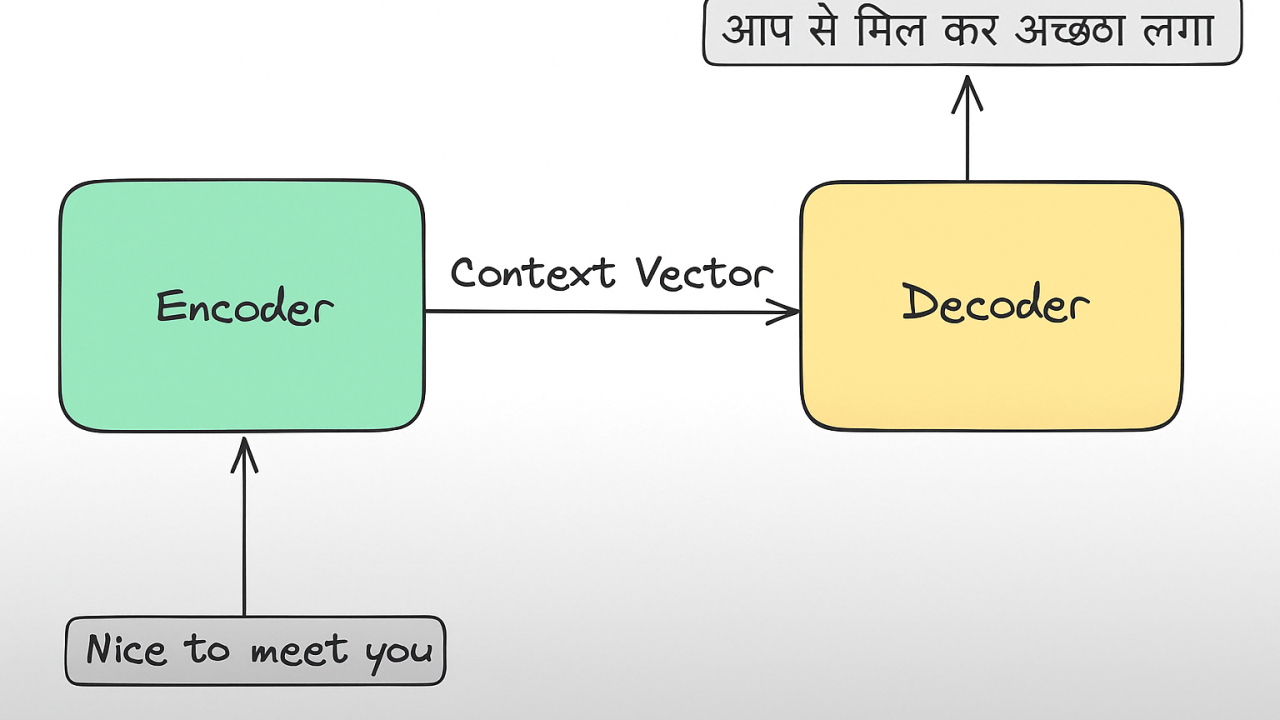
Kiến trúc Seq2Seq cơ bản với Encoder-Decoder sử dụng RNN hoặc LSTM.
**Ứng dụng:**- Dịch máy (Machine Translation): Thành công vang dội, đạt được chất lượng dịch chưa từng có.
- Tóm tắt văn bản (Text Summarization): Biến một văn bản dài thành một bản tóm tắt ngắn.
- Hệ thống hội thoại (Chatbots): Biến câu hỏi thành câu trả lời.
6.3. Vấn đề: "Nút cổ chai" thông tin
Mặc dù Seq2Seq là một bước tiến vượt bậc, nó vẫn mang trong mình một hạn chế nghiêm trọng: "Nút cổ chai thông tin" (Information Bottleneck): Toàn bộ thông tin từ chuỗi đầu vào, bất kể dài bao nhiêu, đều phải được nén vào một vector ngữ cảnh có kích thước cố định duy nhất. Với các câu ngắn, điều này có thể hoạt động tốt. Nhưng với các câu dài và phức tạp, vector cố định này không đủ khả năng chứa đựng tất cả các sắc thái ngữ nghĩa, dẫn đến mất mát thông tin đáng kể. Điều này khiến chất lượng dịch hoặc tóm tắt giảm sút khi xử lý các chuỗi dài.
Vấn đề này đã đặt ra một câu hỏi then chốt: Làm thế nào để Decoder có thể "chọn lọc" thông tin cần thiết từ Encoder một cách linh hoạt, thay vì phải phụ thuộc vào một vector ngữ cảnh tĩnh? Đây chính là mảnh ghép còn thiếu, mở đường cho một cơ chế đột phá: Attention.
7. Attention Mechanism: Cách Mạng Thị Giác Trong NLP (Giữa những năm 2010)
7.1. Động lực: Làm sao để máy tính tập trung đúng chỗ?
Vấn đề nút cổ chai của Seq2Seq đã lộ rõ: thông tin quan trọng bị chôn vùi trong một vector ngữ cảnh cố định, làm Decoder khó lòng tìm thấy các chi tiết cần thiết khi sinh ra chuỗi đầu ra. Con người khi dịch một câu dài, không chỉ nhìn vào "tóm tắt" toàn bộ câu, mà còn "chú ý" đến từng phần của câu gốc khi dịch từng phần tương ứng.
Năm 2015, Dzmitry Bahdanau, Kyunghyun Cho và Yoshua Bengio đã giới thiệu một ý tưởng mang tính cách mạng trong bài báo "Neural Machine Translation by Jointly Learning to Align and Translate": Cơ chế Attention (Chú ý).
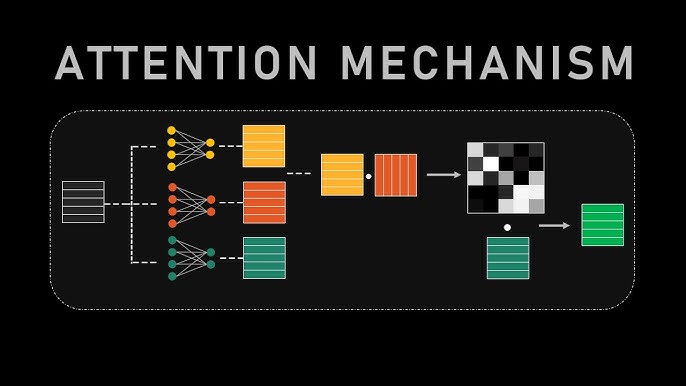
Minh họa cơ chế Attention: cho phép Decoder tập trung vào các phần liên quan của Encoder.
### 7.2. Cách Hoạt Động: Tập trung vào điều quan trọngThay vì nén toàn bộ thông tin của Encoder vào một vector ngữ cảnh duy nhất, Attention cho phép Decoder tại mỗi bước sinh từ chủ động "tìm kiếm" và "chú ý" đến các phần liên quan nhất của chuỗi đầu vào (thông qua các trạng thái ẩn của Encoder).
- Tạo Trọng Số (Alignment Scores): Tại mỗi bước giải mã, Decoder tính toán một "điểm tương đồng" (alignment score) giữa trạng thái ẩn hiện tại của nó và tất cả các trạng thái ẩn của Encoder.
- Phân Phối Trọng Số (Softmax): Các điểm tương đồng này sau đó được chuẩn hóa thành một phân phối xác suất (softmax), tạo ra các trọng số chú ý (attention weights). Các trọng số này cho biết mức độ "quan trọng" của mỗi từ trong chuỗi đầu vào đối với từ mà Decoder đang cố gắng sinh ra.
- Tạo Context Vector Động: Một vector ngữ cảnh mới, động, được tạo ra bằng cách lấy tổng có trọng số của các trạng thái ẩn của Encoder, sử dụng các trọng số chú ý vừa tính toán.
- Decoder Tiếp Tục Sinh Từ: Decoder sử dụng vector ngữ cảnh động này (cùng với trạng thái ẩn và từ trước đó) để dự đoán từ tiếp theo.
Công thức tổng quát cho Attention (sau này được khái quát hóa): Trong đó (Query) là trạng thái hiện tại của Decoder, (Keys) là các trạng thái ẩn của Encoder, và (Values) cũng là các trạng thái ẩn của Encoder.
7.3. Ý nghĩa và tầm ảnh hưởng: Mở khóa tiềm năng của chuỗi dài
Ưu điểm và Tác động:
- Khắc phục nút cổ chai: Đây là giải pháp hoàn hảo cho vấn đề nút cổ chai của Seq2Seq, cho phép xử lý các chuỗi dài một cách hiệu quả hơn nhiều.
- Cải thiện chất lượng: Đặc biệt trong dịch máy, Attention đã cải thiện đáng kể độ chính xác và tính trôi chảy của các bản dịch.
- Khả năng diễn giải (Interpretability): Các trọng số chú ý cung cấp một cái nhìn trực quan về việc mô hình đang "nhìn vào đâu" trong chuỗi đầu vào khi đưa ra quyết định. Điều này giúp các nhà nghiên cứu hiểu rõ hơn về hoạt động bên trong của mô hình.
- Nền tảng cho Transformer: Quan trọng nhất, Attention đã chứng minh được sức mạnh của nó và trở thành viên gạch nền tảng cho kiến trúc đột phá tiếp theo – Transformer.
Attention không chỉ là một cải tiến, nó là một sự thay đổi mô hình tư duy, cho thấy rằng sự tập trung có chọn lọc có thể là chìa khóa để xử lý ngôn ngữ tự nhiên phức tạp. Tuy nhiên, nó vẫn phụ thuộc vào RNN nền tảng, và hạn chế về song song hóa vẫn còn đó.
8. Transformer: "Attention Is All You Need" – cuộc cách mạng của trí tuệ ngôn ngữ (2017)
8.1. Động lực: Khi sự tuần tự trở thành rào cản
Mặc dù LSTM/GRU với Attention đã đạt được những thành công vang dội, đặc biệt trong dịch máy, nhưng chúng vẫn mang một gánh nặng cố hữu của các mô hình RNN: tính tuần tự. Để tính toán đầu ra tại bước , bạn phải đợi kết quả từ bước . Điều này không chỉ làm chậm quá trình huấn luyện và suy luận, mà còn cản trở việc tận dụng tối đa sức mạnh của các kiến trúc phần cứng hiện đại như GPU, vốn được thiết kế cho các phép tính song song.
Các nhà nghiên cứu tại Google, đứng đầu là Ashish Vaswani, đã đặt ra một câu hỏi táo bạo: Nếu Attention mạnh mẽ đến vậy, liệu chúng ta có thể loại bỏ hoàn toàn các cơ chế lặp (recurrence) và chập (convolution) và chỉ dựa vào Attention để xây dựng một mô hình ngôn ngữ không? Câu trả lời là CÓ, và nó đã được công bố vào năm 2017 với bài báo mang tính biểu tượng: "Attention Is All You Need."
8.2. Kiến Trúc: Độc lập, song song và mạnh mẽ
Transformer loại bỏ hoàn toàn các RNN/CNN và xây dựng toàn bộ mô hình dựa trên cơ chế Attention. Nó sử dụng một kiến trúc Encoder-Decoder tương tự Seq2Seq, nhưng cả Encoder và Decoder đều được cấu thành từ các lớp (layer) chỉ sử dụng các khối Attention.
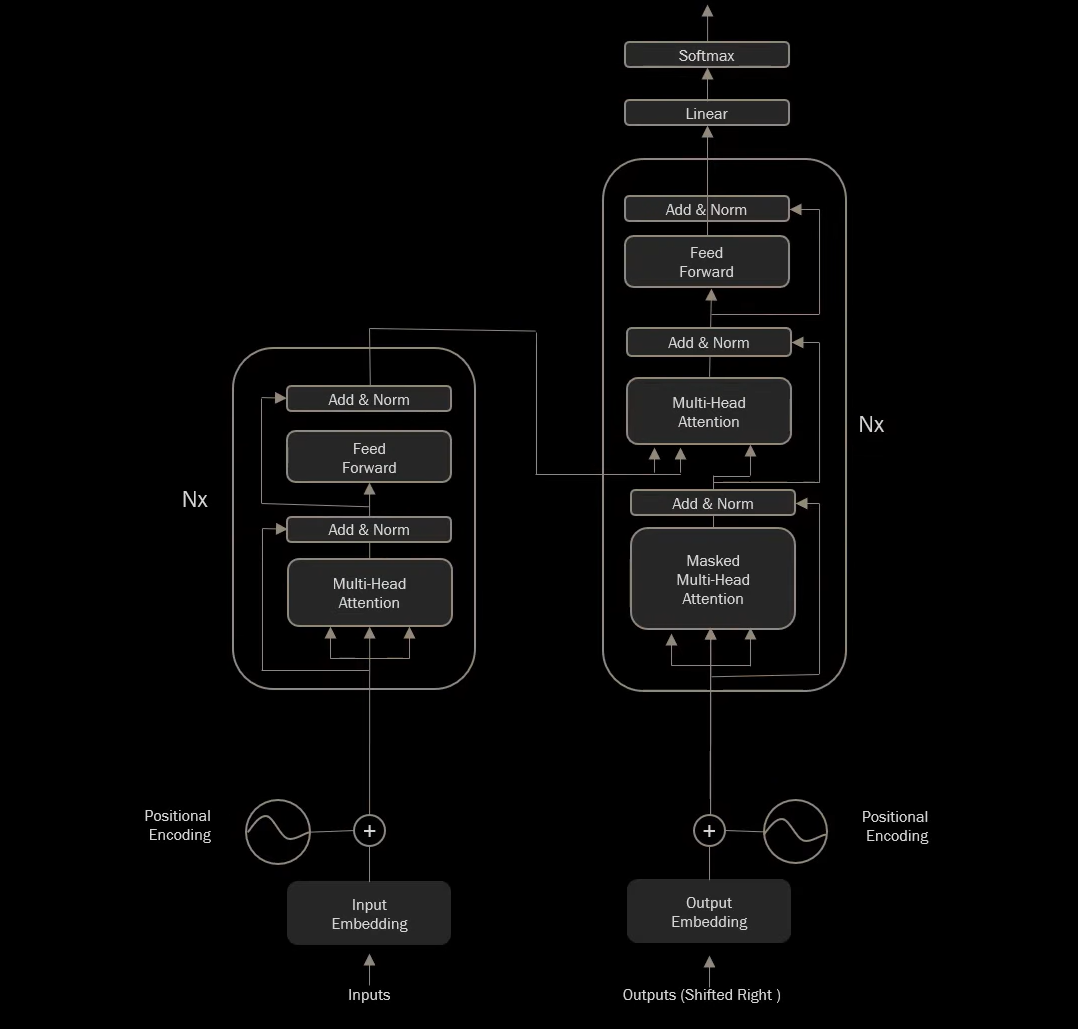
Transformer với Self-Attention và cấu trúc Encoder-Decoder.
Các thành phần cốt lõi của Transformer:- Self-Attention (Tự Chú Ý): Đây là trái tim của Transformer. Khác với Attention trong Seq2Seq (từ Decoder nhìn sang Encoder), Self-Attention cho phép mỗi từ trong một chuỗi đầu vào tự "chú ý" đến tất cả các từ khác trong chính chuỗi đó. Điều này giúp mô hình nắm bắt các mối quan hệ ngữ pháp và ngữ nghĩa giữa các từ ở xa nhau trong một câu. Ví dụ, trong câu "Con sông chảy êm đềm, nó uốn lượn quanh ngọn đồi", khi xử lý từ "nó", Self-Attention sẽ cho phép mô hình liên kết "nó" với "con sông".
- Cơ chế Self-Attention tính toán ba vector cho mỗi từ: Query (Q), Key (K), Value (V). Sự tương tác giữa Q của một từ và K của các từ khác xác định trọng số chú ý, sau đó được sử dụng để tổng hợp các V.
- Multi-Head Attention (Chú Ý Đa Đầu): Thay vì chỉ có một cơ chế Self-Attention, Transformer sử dụng nhiều "đầu" Attention song song. Mỗi đầu học cách "chú ý" đến các khía cạnh khác nhau của mối quan hệ giữa các từ. Ví dụ, một đầu có thể tập trung vào quan hệ cú pháp (động từ - tân ngữ), đầu khác vào quan hệ ngữ nghĩa (từ đồng nghĩa). Sau đó, kết quả từ các đầu được kết hợp lại.
- Positional Encoding (Mã Hóa Vị Trí): Vì Transformer cho phép song song hóa mạnh hơn ở bước huấn luyện so với RNN, nó không có thông tin về thứ tự từ. Positional Encoding là các vector được cộng vào embedding của mỗi từ để cung cấp thông tin về vị trí tương đối và tuyệt đối của từ trong chuỗi.
- Feed-Forward Networks: Sau mỗi khối Attention, có một mạng truyền thẳng (MLP) áp dụng cùng một phép biến đổi cho mỗi vị trí từ riêng biệt.
- Residual Connections & Layer Normalization: Giúp ổn định quá trình huấn luyện các mạng sâu.
8.3. Ưu và nhược điểm: Vô song về tốc độ và khả năng mở rộng
Ưu điểm mang tính cách mạng:
- Song song hóa triệt để: Vì không có vòng lặp tuần tự, tất cả các từ trong chuỗi có thể được xử lý đồng thời. Điều này giúp tăng tốc độ huấn luyện và suy luận lên đáng kể, cho phép huấn luyện trên các tập dữ liệu khổng lồ trong thời gian ngắn hơn.
- Nắm bắt phụ thuộc dài hạn hiệu quả: Với Self-Attention, mỗi từ có thể trực tiếp tương tác với mọi từ khác trong chuỗi, giải quyết triệt để vấn đề phụ thuộc dài hạn mà RNN gặp phải.
- Tính linh hoạt và khả năng mở rộng: Kiến trúc Transformer rất linh hoạt, có thể dễ dàng chồng nhiều lớp lên nhau để tăng cường sức mạnh mô hình, và đặc biệt hiệu quả khi mở rộng quy mô dữ liệu và tham số.
- Giảm thiểu lỗi trong dịch máy: Ngay từ khi ra đời, Transformer đã thiết lập các kỷ lục mới về chất lượng dịch máy.
Nhược điểm:
- Chi phí tính toán tăng theo bình phương độ dài chuỗi (Quadratic Complexity): Với Self-Attention gốc, chi phí tính toán và bộ nhớ tăng theo bình phương độ dài chuỗi đầu vào ($O(N^2)$). Điều này gây khó khăn khi xử lý các chuỗi cực dài (ví dụ: toàn bộ cuốn sách). Các cải tiến như Longformer, Reformer, Performer, và gần đây là FlashAttention (do Tri Dao, một nhà nghiên cứu gốc Việt tại Stanford, đề xuất) đã ra đời để giảm thiểu vấn đề này. FlashAttention đặc biệt nổi bật vì tối ưu truy cập bộ nhớ GPU, giúp tăng tốc độ huấn luyện và suy luận mà vẫn giữ nguyên tính chính xác, được tích hợp rộng rãi trong nhiều framework lớn (như PyTorch, Hugging Face Transformers). (Mình sẽ có một blog riêng phân tích chi tiết về FlashAttention trong thời gian tới).
- Thiếu ngữ cảnh cục bộ ban đầu: Mặc dù Self-Attention nhìn toàn cục, nhưng ban đầu nó không có "cửa sổ nhìn" cục bộ như CNN. Điều này đã được giải quyết bằng cách huấn luyện mô hình trên dữ liệu lớn hoặc kết hợp các cơ chế khác.
Transformer không chỉ là một kiến trúc mới, nó đã khơi mào cho một kỷ nguyên vàng mới trong NLP, thay đổi hoàn toàn cách chúng ta tiếp cận các bài toán ngôn ngữ và trở thành nền tảng cho sự phát triển của Trí tuệ nhân tạo tổng quát.
9. Thời đại mô hình dựa trên Transformer: Sự bùng nổ của kiến thức (2018 – Hiện tại)
Thành công vang dội của Transformer đã nhanh chóng mở ra một chương mới: kỷ nguyên của các mô hình tiền huấn luyện quy mô lớn. Các nhà nghiên cứu nhận ra rằng, với kiến trúc Transformer mạnh mẽ, chúng ta có thể huấn luyện các mô hình trên một lượng dữ liệu văn bản khổng lồ (vài terabyte) để chúng học được ngữ pháp, ngữ nghĩa, và cả kiến thức thế giới. Sau đó, các mô hình này có thể được "tinh chỉnh" (fine-tuned) cho các tác vụ cụ thể với dữ liệu nhỏ hơn.
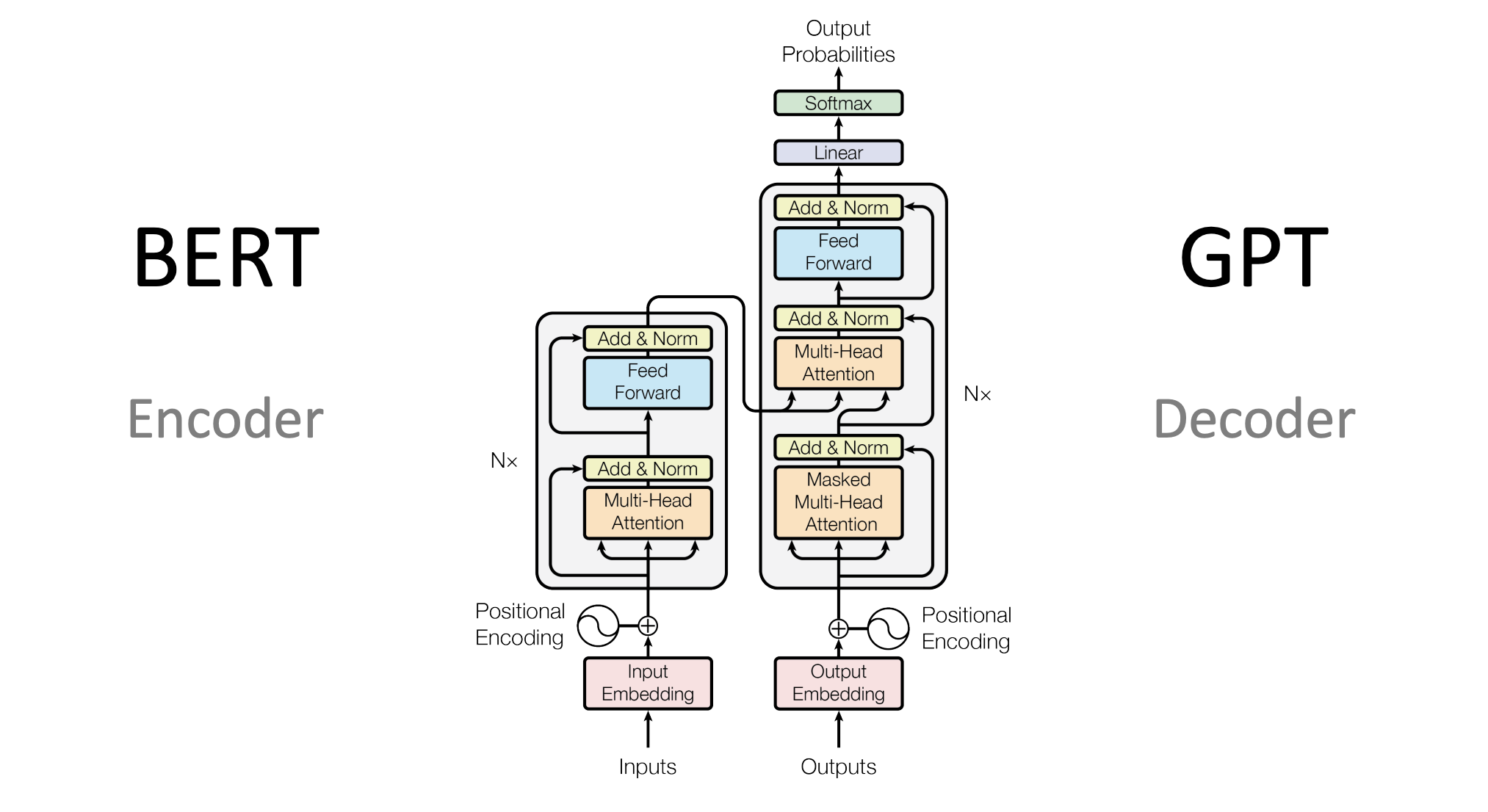
BERT tập trung vào hiểu ngữ cảnh hai chiều, GPT chuyên về sinh văn bản một chiều.
### 9.1. BERT (Bidirectional Encoder Representations from Transformers – Google, 2018)- Kiến trúc: Chỉ sử dụng phần Encoder của Transformer.
- Phương pháp huấn luyện đột phá:
- Masked Language Model (MLM): Thay vì dự đoán từ tiếp theo, BERT che đi (mask) một số từ trong câu và yêu cầu mô hình dự đoán các từ bị che. Điều này buộc mô hình phải hiểu ngữ cảnh hai chiều (bidirectional) của từ.
- Next Sentence Prediction (NSP): Mô hình cũng học cách dự đoán liệu hai câu có theo sau nhau trong văn bản gốc hay không.
- Mục tiêu: Tập trung vào hiểu ngôn ngữ (language understanding).
- Ứng dụng: Đạt kỷ lục mới trên 11 tác vụ NLP như Hỏi đáp (Question Answering), phân loại văn bản, nhận dạng thực thể có tên.
9.2. GPT (Generative Pre-trained Transformer – OpenAI, 2018 – nay)
- Kiến trúc: Chỉ sử dụng phần Decoder của Transformer (với masked self-attention để đảm bảo chỉ nhìn vào các từ đã sinh).
- Phương pháp huấn luyện: Autoregressive Language Modeling: Dự đoán từ tiếp theo trong chuỗi một cách tuần tự.
- Mục tiêu: Tập trung vào sinh ngôn ngữ (language generation).
- Sự tiến hóa:
- GPT-1: Mô hình đầu tiên chứng minh sức mạnh của pre-training/fine-tuning cho việc sinh ngôn ngữ.
- GPT-2 (2019): Với 1.5 tỷ tham số, gây chấn động về khả năng sinh văn bản mạch lạc, thuyết phục đến mức OpenAI ban đầu e ngại phát hành phiên bản đầy đủ.
- GPT-3 (2020): 175 tỷ tham số. Chứng minh khả năng "học trong ngữ cảnh" (in-context learning) – thực hiện các tác vụ chỉ bằng cách xem vài ví dụ trong lời nhắc, không cần tinh chỉnh thêm. Bắt đầu xuất hiện các khả năng bất ngờ (emergent abilities).
- GPT-4 (2023): Thậm chí mạnh mẽ hơn, đa phương thức (xử lý cả văn bản và hình ảnh), và thể hiện khả năng suy luận phức tạp.
9.3. Các mô hình Transformer-based khác
- T5 (Text-to-Text Transfer Transformer – Google, 2019): Chuẩn hóa mọi tác vụ NLP thành định dạng "text-to-text", sử dụng kiến trúc Encoder-Decoder đầy đủ.
- BART (Bidirectional and Auto-Regressive Transformers – Facebook AI, 2019): Kết hợp các ý tưởng từ BERT và GPT, phù hợp cho cả hiểu và sinh ngôn ngữ.
- RoBERTa, ALBERT, ELECTRA, XLNet...: Hàng loạt các biến thể và cải tiến của BERT, tối ưu hóa huấn luyện hoặc kiến trúc.
9.4. Vượt ra ngoài NLP: Vision Transformer (ViT) và mô hình đa phương thức
Sức mạnh của Transformer không chỉ dừng lại ở ngôn ngữ.
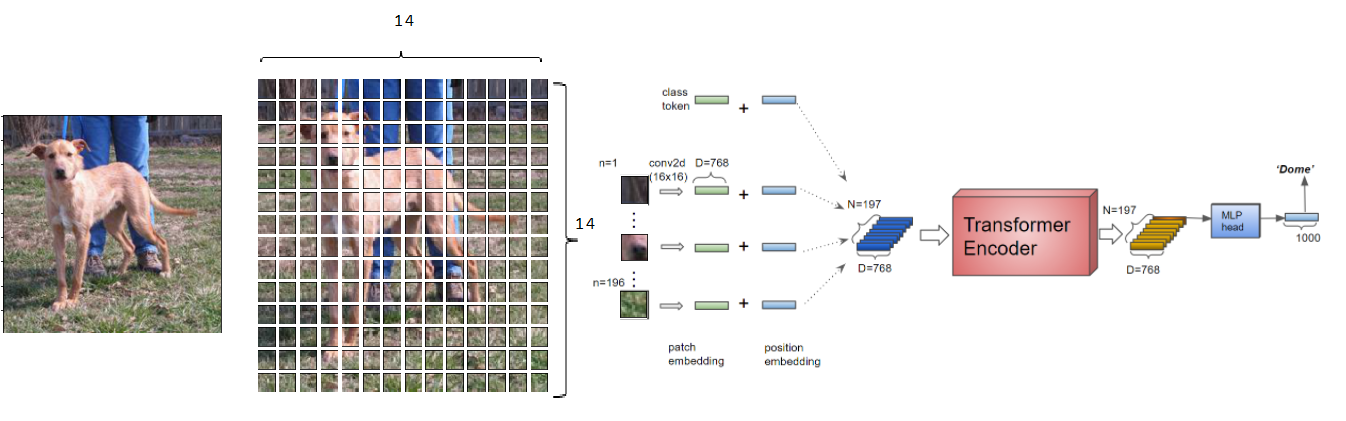
ViT – Ứng dụng kiến trúc Transformer vào xử lý ảnh thay cho CNN truyền thống.
- **Vision Transformer (ViT – Google, 2020):** Áp dụng kiến trúc Transformer để xử lý hình ảnh, phá vỡ thế độc tôn của mạng CNN trong thị giác máy tính. - **Multimodal Transformers (CLIP, DALL-E, GPT-4o, Gemini):** Các mô hình có thể hiểu và kết nối thông tin từ nhiều phương thức khác nhau (văn bản, hình ảnh, âm thanh), mở ra kỷ nguyên của AI đa năng.10. Kỷ Nguyên LLM: Trí tuệ sáng tạo và đa năng (Đầu những năm 2020 – Hiện tại)
Sự phát triển vượt bậc của các mô hình dựa trên Transformer đã dẫn chúng ta đến một kỷ nguyên mới: Kỷ nguyên của các Mô hình Ngôn ngữ Lớn (Large Language Models – LLM). Đây không chỉ là một sự gia tăng về kích thước, đó là một sự thay đổi về chất, một bước nhảy vọt trong khả năng của AI.
10.1. Đặc trưng của LLM
- Quy mô Khổng Lồ: Hàng chục, hàng trăm, thậm chí hàng nghìn tỷ tham số.
- Dữ liệu Huấn Luyện Bao La: Được huấn luyện trên hàng terabyte dữ liệu văn bản và mã nguồn từ internet (sách, bài báo, web, code...), giúp chúng hấp thụ một lượng tri thức khổng lồ.
- Khả Năng Bất Ngờ (Emergent Abilities): Khi LLM đạt đến một quy mô nhất định, chúng bắt đầu thể hiện những khả năng không được lập trình rõ ràng hoặc không dự đoán được từ các mô hình nhỏ hơn. Ví dụ:
- Suy luận chuỗi (Chain-of-Thought Reasoning): Khả năng thực hiện các bước suy luận logic để giải quyết vấn đề phức tạp.
- Sinh mã nguồn (Code Generation): Viết code, gỡ lỗi, giải thích code.
- Sáng tạo nội dung (Creative Content Generation): Viết thơ, kịch bản, bài hát.
- Đối thoại tự nhiên: Duy trì cuộc trò chuyện mạch lạc, có ngữ cảnh.
- Khả năng "học trong ngữ cảnh" (In-Context Learning): Có thể học và thực hiện một tác vụ mới chỉ bằng vài ví dụ trong lời nhắc, không cần tinh chỉnh lại toàn bộ mô hình.
10.2. Những "Ông Lớn" định hình kỷ nguyên
- GPT (OpenAI): Tiên phong và dẫn đầu về khả năng tạo sinh và hiểu ngôn ngữ.
- LLaMA (Meta): Các mô hình mã nguồn mở mạnh mẽ, thúc đẩy cộng đồng nghiên cứu và phát triển AI.
- Claude (Anthropic): Tập trung vào an toàn và hữu ích, với khả năng xử lý ngữ cảnh dài.
- Gemini (Google DeepMind): Mô hình đa phương thức tiên tiến, tích hợp ngôn ngữ, hình ảnh, âm thanh, video.
- Mistral, Falcon, xAI...: Nhiều "tay chơi" mới nổi, liên tục đẩy ranh giới của LLM.
10.3. Tác động sâu rộng
LLM đang định hình lại nhiều lĩnh vực: từ giáo dục (gia sư AI), y tế (hỗ trợ chẩn đoán), lập trình (hỗ trợ viết code), sáng tạo nghệ thuật, đến giao tiếp cá nhân. Chúng không chỉ là công cụ dự đoán từ ngữ, chúng đang trở thành những "trợ lý tư duy" mạnh mẽ.
11. Tương lai của mô hình ngôn ngữ: Hướng tới trí tuệ tổng quát (AGI)
Hành trình từ N-gram đến LLM là một minh chứng hùng hồn cho khát vọng không ngừng nghỉ của con người trong việc thấu hiểu và mô phỏng trí tuệ. Tuy nhiên, đây mới chỉ là khởi đầu. Tương lai của mô hình ngôn ngữ hứa hẹn những bước tiến còn ngoạn mục hơn:
- Hiệu Quả Hóa và Tiết Kiệm Năng Lượng: LLM hiện tại rất tốn kém về tài nguyên và năng lượng. Tương lai sẽ chứng kiến sự phát triển của các mô hình nhỏ gọn hơn (Small Language Models - SLM, Nano-LLM), hiệu quả hơn, có thể chạy trên các thiết bị cá nhân (on-device AI) hoặc với chi phí vận hành thấp hơn đáng kể, đồng thời vẫn giữ được khả năng mạnh mẽ.
- Đa Phương Thức (Multimodality) Toàn Diện: Mở rộng từ văn bản và hình ảnh sang âm thanh, video, cảm biến và thậm chí là hành động trong thế giới vật lý. Mô hình sẽ không chỉ "hiểu" thế giới qua văn bản mà còn "cảm nhận" và "tương tác" qua nhiều giác quan, tạo nên trí tuệ toàn diện hơn.
- Tích Hợp Tri Thức Ngoài và Giảm "Ảo Giác": LLM hiện tại có thể "bịa đặt" thông tin (hallucination). Tương lai, các mô hình sẽ được tích hợp sâu hơn với các nguồn tri thức bên ngoài (ví dụ: công cụ tìm kiếm, cơ sở dữ liệu tri thức) thông qua các kỹ thuật như Retrieval-Augmented Generation (RAG), giúp chúng cung cấp thông tin chính xác, đáng tin cậy và có khả năng tham chiếu.
- An Toàn, Kiểm Soát và Đạo Đức: Với sức mạnh ngày càng tăng, việc đảm bảo AI an toàn, công bằng, không thiên vị và có thể kiểm soát được trở thành ưu tiên hàng đầu. Các nghiên cứu sẽ tập trung vào việc giảm thiểu rủi ro, kiểm duyệt nội dung độc hại và căn chỉnh AI với các giá trị của con người.
- Hướng Tới Trí Tuệ Nhân Tạo Tổng Quát (AGI): Mục tiêu cuối cùng là từ việc dự đoán ngôn ngữ, mô hình sẽ phát triển thành một hệ thống có khả năng tư duy, học hỏi, và thích ứng với mọi tác vụ trí tuệ của con người. LLM đang cung cấp những gợi ý đầu tiên về cách AGI có thể được xây dựng.
AGI – Tương lai nơi AI vượt khỏi giới hạn ngôn ngữ và tiến gần trí tuệ con người.
Một mành trình vĩ đại, một tương lai bất tận
Hành trình hình thành và phát triển của mô hình ngôn ngữ là một câu chuyện sử thi về nỗ lực không ngừng nghỉ của con người để vượt qua những giới hạn, từ bỏ những định kiến cũ và kiến tạo những ý tưởng đột phá.
- Chúng ta đã đi từ sự đơn giản nhưng cục bộ của N-gram thống kê, chỉ nhìn thấy từng mảnh rời rạc của ngôn ngữ.
- Đến sự ra đời của NNLM và embedding, giúp máy tính lần đầu tiên "cảm nhận" được ý nghĩa sâu sắc và mối quan hệ liên tục giữa các từ.
- Tiếp đó là RNN với "bộ nhớ" tuần tự, cố gắng nắm bắt dòng chảy thời gian của ngôn ngữ, dù còn gặp nhiều khó khăn.
- LSTM và GRU đã giải cứu RNN khỏi vấn đề "quên lãng", mở ra kỷ nguyên mới cho việc xử lý chuỗi dài.
- Seq2Seq đã biến đổi khái niệm mô hình ngôn ngữ thành một "phiên dịch viên" mạnh mẽ.
- Và rồi, Attention xuất hiện như một "ánh mắt thông minh", giải quyết nút cổ chai, mở đường cho cuộc cách mạng thực sự.
- Cuối cùng, Transformer đã phá vỡ xiềng xích tuần tự, mang đến tốc độ, song song hóa và khả năng hiểu biết sâu rộng, dẫn đến sự bùng nổ của các mô hình khổng lồ như BERT, GPT, Gemini.
Ngày nay, những LLM không còn chỉ là công cụ dự đoán từ. Chúng đang trở thành những "người bạn đồng hành trí tuệ" có khả năng sáng tạo, suy luận, và thấu hiểu. Tương lai của mô hình ngôn ngữ không chỉ nằm ở việc chúng ta có thể làm được gì với chúng, mà còn ở việc chúng sẽ định hình lại cách chúng ta học hỏi, làm việc, giao tiếp và thậm chí là định nghĩa lại chính trí tuệ nhân tạo. Hành trình này vẫn đang tiếp diễn, và mỗi chúng ta đều đang là một phần của nó.
Related Articles
Discover more articles related to this topic

Diffusion vs Flow Matching vs Optimal Transport
Phân tích tổng quan sự khác nhau và điểm tương đồng giữa Diffusion, Flow Matching và Optimal Transport dưới góc nhìn chuyển động của phân phối xác suất, từ hàm mất mát đến quá trình lấy mẫu.

MemVerse: Multimodal Memory và con đường hướng tới Lifelong Learning Agents
Phân tích MemVerse – một framework bộ nhớ đa phương thức cho AI Agents học tập suốt đời, kết hợp Knowledge Graph truy xuất và Parametric Memory để giải quyết bài toán catastrophic forgetting, tối ưu suy luận đa phương thức và tương tác dài hạn.

Fractal Dimension: Khi chiều không gian vượt thoát khỏi khuôn khổ số nguyên
Khám phá chiều fractal – một khái niệm đột phá trong hình học, vượt ra ngoài khuôn khổ số nguyên để mô tả sự phức tạp của tự nhiên. Bài viết đi sâu vào lịch sử, cơ sở toán học và vô vàn ứng dụng của fractal trong sinh học, vật lý, kinh tế và đặc biệt là khoa học máy tính và AI.

“Kỹ thuật là cách thế phơi lộ”: khi công nghệ định hình tự do của chúng ta
Heidegger từng nói kỹ thuật không chỉ là công cụ trong tay con người, mà là tấm gương định hình cách ta nhìn và sống trong thế giới. Ngày nay, khi trí tuệ nhân tạo bắt đầu can thiệp vào cách ta học hỏi, sáng tạo và ra quyết định, câu hỏi lớn vẫn vang vọng: liệu AI đang giúp chúng ta mở ra những lối đi mới, hay đang âm thầm dựng nên một chiếc lồng vô hình bủa vây tự do và suy tưởng của chính con người?
Discover all 6 articles in our blog