Diffusion vs Flow Matching vs Optimal Transport
Phân tích tổng quan sự khác nhau và điểm tương đồng giữa Diffusion, Flow Matching và Optimal Transport dưới góc nhìn chuyển động của phân phối xác suất, từ hàm mất mát đến quá trình lấy mẫu.

Nhà điêu khắc vĩ đại Michelangelo từng nói rằng, mỗi khối đá cẩm thạch đều ẩn chứa bên trong một bức tượng, và nhiệm vụ của người nghệ sĩ chỉ đơn giản là đục bỏ đi những phần thừa thãi. Trong kỷ nguyên của Trí tuệ Nhân tạo, các mô hình sinh (Generative Models) cũng hoạt động theo một triết lý tương tự. Thay vì đá cẩm thạch, chất liệu ban đầu của máy tính là nhiễu ngẫu nhiên, những điểm ảnh nhiễu vô nghĩa giống như màn hình TV mất sóng. Và bức tượng hiện ra ở cuối quá trình, chính là những kiệt tác hình ảnh sắc nét, chân thực đến ngỡ ngàng.
Nhưng máy tính không dùng búa và đục. Nó dùng toán học.
Trong vài năm trở lại đây, thế giới AI chứng kiến sự trỗi dậy mạnh mẽ của các thuật toán sinh ảnh. Bạn có thể đã nghe đến Midjourney, DALL-E hay Stable Diffusion. Gần đây hơn, những hệ mới như ChatGPT Images 2.0 hay Nano Banana 2 cũng cho thấy chất lượng hình ảnh và khả năng kiểm soát ngày càng tốt hơn, từ tạo ảnh hoàn chỉnh đến chỉnh sửa, thiết kế và dựng layout phức tạp. Dù khác nhau về cách triển khai, phần lớn các hệ này đều dựa trên cùng một ý tưởng nền tảng: mô hình hóa sự thay đổi của phân phối xác suất theo thời gian. Tuy nhiên, đằng sau đó là nhiều hướng tiếp cận khác nhau và cũng là một cuộc tranh luận sôi nổi giữa các nhà nghiên cứu: Nên sử dụng Diffusion, Flow Matching hay Optimal Transport? Và đến nay vẫn chưa có câu trả lời dứt khoát cho việc phương pháp nào là tốt nhất trong mọi trường hợp.
1. Hai cách mô tả sự thay đổi của dữ liệu: Lagrangian và Eulerian
Để hiểu cách máy tính tạo ra ảnh, ta phải hiểu cách nó di chuyển dữ liệu. Hãy tưởng tượng bạn đang đổ một giọt mực vào cốc nước. Quá trình giọt mực tan ra (từ một hình dáng rõ ràng thành một màu đồng nhất) chính là quá trình thêm nhiễu (forward process). Máy tính học cách đảo ngược quá trình này: gom màu sắc từ cốc nước hòa tan để tái tạo lại giọt mực ban đầu (reverse process).
Giáo sư Gabriel Peyré đã đưa ra một phép ẩn dụ tuyệt đẹp để mô tả quá trình này thông qua hai lăng kính vật lý:
- Góc nhìn Lagrangian (Hạt): Bạn chọn một hạt mực duy nhất và bám theo nó. Bạn ghi chép lại quỹ đạo của nó khi nó trôi dạt trong nước. Đây là cách ta theo dõi sự dịch chuyển qua một trường vector.
- Góc nhìn Eulerian (Mật độ): Bạn đứng yên một chỗ và quan sát mật độ của toàn bộ đám mây mực thay đổi như thế nào tại điểm đó theo thời gian. Đây là bài toán của các phương trình đạo hàm riêng (PDE), cụ thể là phương trình liên tục.
Vấn đề cốt lõi của AI sinh ảnh là: Có vô số quỹ đạo hạt (trường vector) có thể tạo ra cùng một sự thay đổi mật độ từ nhiễu sang dữ liệu. Nhiệm vụ của chúng ta là tìm ra một quỹ đạo dễ học nhất, ít tốn kém nhất cho mạng nơ-ron.
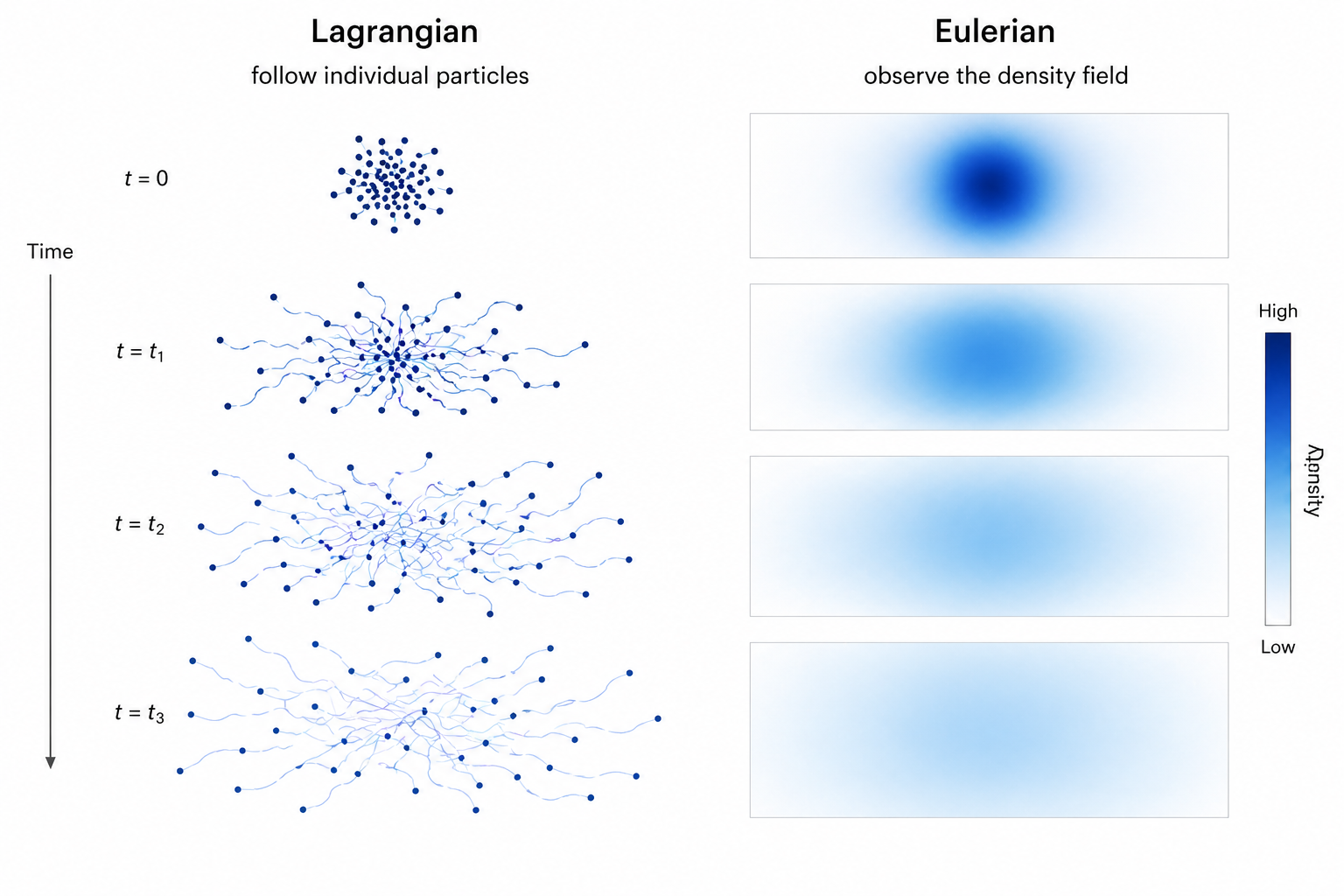
Hai góc nhìn tương đương của chuyển động phân phối: Lagrangian theo dõi quỹ đạo từng hạt, trong khi Eulerian quan sát sự biến đổi mật độ theo thời gian.
2. Diffusion và Flow Matching: giống nhau nhiều hơn bạn nghĩ
Khi Mô hình Khuếch tán (Diffusion Models) ra đời, nó đã tạo ra một cuộc cách mạng. Nó hoạt động bằng cách chẻ nhỏ quá trình khử nhiễu thành hàng ngàn bước lặp đi lặp lại. Quỹ đạo mà nó tạo ra thường cong và mang tính ngẫu nhiên (stochastic).
Sau đó, Flow Matching xuất hiện, mang theo một lời hứa hấp dẫn: Nó có thể tạo ra các quỹ đạo là những đường thẳng nối trực tiếp từ nhiễu đến dữ liệu. Trong một thời gian, cộng đồng AI đã chia phe, tự hỏi thuật toán nào ưu việt hơn.
Nhưng khoa học luôn có cách khiến chúng ta phải kinh ngạc. Trong bài viết Diffusion Meets Flow Matching, các nhà nghiên cứu tại Google DeepMind đã rút ra một nhận xét quan trọng: Diffusion và Flow Matching có thể trở nên tương đương trong một số thiết lập, đặc biệt khi sử dụng nhiễu Gauss và cách chọn trọng số phù hợp trong hàm mất mát.
- Sự tương đồng về hàm mất mát: Khi chọn đường đi Gaussian giữa nhiễu và dữ liệu, và điều chỉnh trọng số theo thời gian trong Flow Matching, mục tiêu huấn luyện của nó có thể viết lại thành dạng tương đương với objective dự đoán nhiễu (noise prediction) trong Diffusion.
- Sự tương đồng về lấy mẫu: Khi viết Diffusion dưới dạng ODE (probability flow ODE), việc lấy mẫu bằng Euler trong Flow Matching cho kết quả tương đương với phương pháp DDIM trong một số thiết lập.
- Hiểu sai phổ biến về quỹ đạo "đường thẳng": Người ta hay truyền tai nhau rằng Flow Matching có quỹ đạo thẳng hoàn hảo. Sự thật là, đường đi chỉ thẳng khi mô hình dự đoán chính xác một điểm dữ liệu duy nhất. Trong thực tế, vì không gian dữ liệu hình ảnh vô cùng phức tạp, quỹ đạo của Flow Matching vẫn bị bẻ cong. Trong một số thiết lập với nhiễu Gaussian (Variance Preserving), quỹ đạo trung bình của Diffusion có thể gần tuyến tính hơn so với các đường đi được học bởi Flow Matching.
Hai cách tiếp cận này không hẳn là đối lập nhau. Trong những thiết lập nhất định, chúng mô tả cùng một quá trình dưới hai góc nhìn khác nhau.
3. Optimal Transport: tìm đường đi tối ưu cho dữ liệu
Nếu Diffusion bắt đầu từ một quá trình thêm nhiễu được thiết kế sẵn (thường là nhiễu Gauss), và Flow Matching học một trường vector dựa trên một đường đi được chọn trước giữa hai phân phối, thì Optimal Transport (OT) tiếp cận vấn đề theo hướng khác: tìm trực tiếp đường đi tối ưu giữa hai phân phối.
Năm 1781, Gaspard Monge, một nhà toán học người Pháp, đối mặt với bài toán: Làm thế nào để di chuyển đất từ một đống vật liệu để đắp thành một pháo đài với tổng chi phí vận chuyển là nhỏ nhất? Hơn hai thế kỷ sau, bài toán chuyển đất của Monge đã trở thành công cụ tối thượng trong Machine Learning để đo lường và dịch chuyển thông tin giữa các không gian phân phối.
Khác với Diffusion vốn dĩ mù quáng đi theo một lịch trình nhiễu, Optimal Transport tìm kiếm con đường ngắn nhất, ít tốn năng lượng nhất. Toán học của OT (thông qua công thức Benamou-Brenier) đảm bảo rằng:
- Các hạt dữ liệu di chuyển theo các quỹ đạo tối ưu (geodesic) trong không gian phân phối, trong một số trường hợp đơn giản, các quỹ đạo này gần tuyến tính.
- Trong thiết lập ánh xạ tối ưu dạng Monge, các quỹ đạo không giao nhau.
Hãy hình dung: Diffusion giống như việc bạn cố gắng đi qua một khu rừng sương mù, nơi đó bạn phải dò dẫm từng bước nhỏ, đôi khi đi đường vòng để tránh chướng ngại vật (đòi hỏi số bước lấy mẫu rất lớn). Ngược lại, Optimal Transport cung cấp cho bạn một lộ trình bay thẳng băng qua cánh rừng. Nhờ đường đi thẳng và đơn giản, nếu ta áp dụng được OT vào AI sinh ảnh, ta có thể sinh ra hình ảnh với các bước nhảy (time steps) cực lớn, giải quyết bài toán thời gian sinh ảnh chậm chạp của Diffusion hiện tại.
Tuy nhiên, không có bữa trưa nào miễn phí. Việc tính toán đường đi OT hoàn hảo trong không gian hàng triệu chiều của hình ảnh là một cơn ác mộng về mặt tính toán.
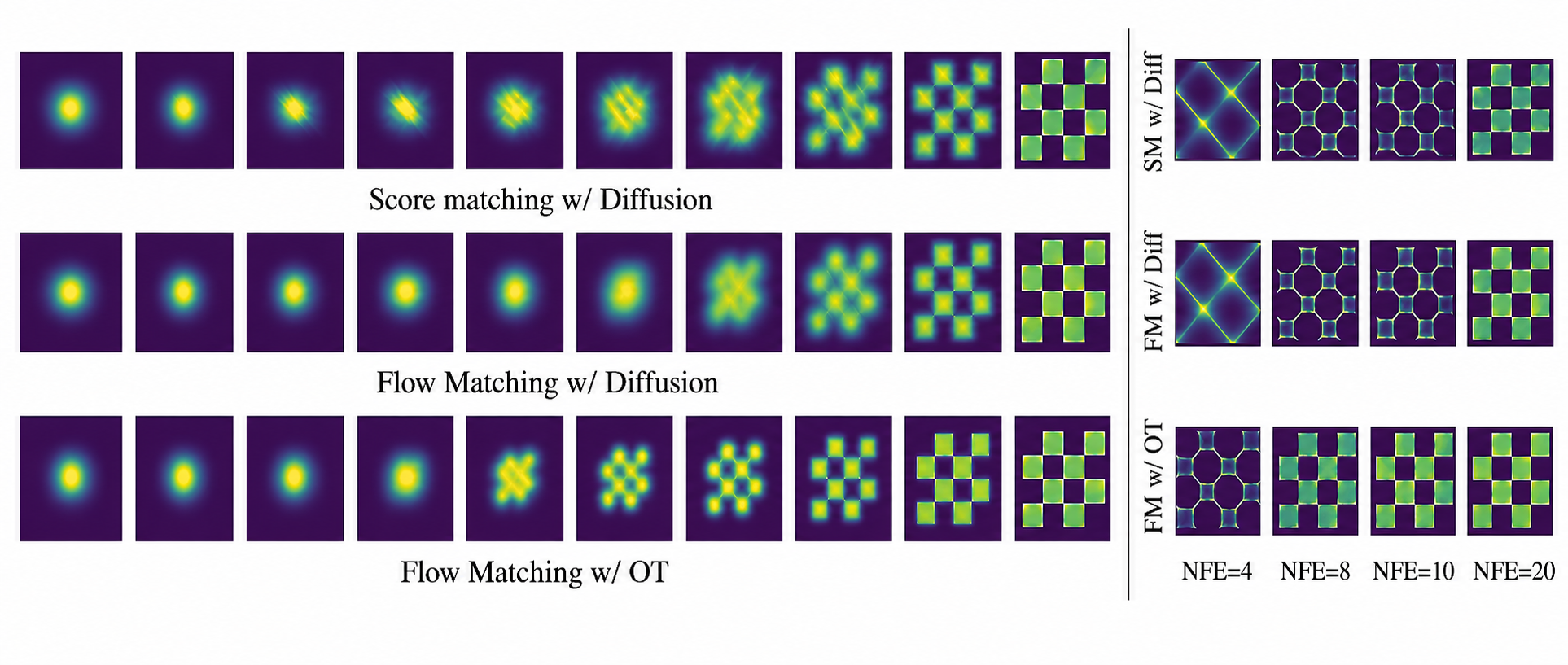
Optimal Transport định hướng các mẫu đi theo quỹ đạo tối ưu trong không gian phân phối, giúp hội tụ nhanh hơn và đạt cấu trúc rõ ràng với ít bước hơn so với Diffusion.
4. OTCS: dùng Optimal Transport để cải thiện Diffusion
Vậy điều gì sẽ xảy ra nếu ta kết hợp bộ máy sinh ảnh mạnh mẽ của Diffusion với khả năng của Optimal Transport? Đó chính là ý tưởng đằng sau mô hình OTCS (Optimal Transport-Guided Conditional Score-Based Diffusion Model).
Bài báo này giải quyết một vấn đề trong thực tế. Các mô hình dịch ảnh (ví dụ: biến ảnh mờ thành ảnh sắc nét, hay biến ảnh phong cảnh mùa hè thành mùa đông) thường cần dữ liệu cặp (paired data). Máy tính cần hàng ngàn cặp ảnh "mờ-nét" khớp nhau chính xác từng pixel để học. Nhưng trong thế giới thực, tìm đâu ra đủ cặp dữ liệu hoàn hảo như vậy?
- Giải pháp của OTCS: Khi đối mặt với bộ dữ liệu không theo cặp (unpaired), OTCS sử dụng Optimal Transport để tạo ra một hàm tương thích (compatibility function - ). Nó giống như một "bà mối" toán học: Nó nhìn vào tập ảnh mờ và tập ảnh nét, sau đó tính toán xác suất (soft coupling) xem một bức ảnh mờ cụ thể có "duyên" nhất với bức ảnh nét nào ở tập bên kia.
- Chiến lược Resampling-by-compatibility: Thay vì để Diffusion học từ các cặp dữ liệu ngẫu nhiên, OTCS sử dụng hàm tương thích để đo mức độ "phù hợp" giữa hai mẫu từ hai tập dữ liệu khác nhau (ví dụ: ảnh mờ và ảnh nét). Hàm này cho điểm cao nếu hai ảnh có cấu trúc hoặc nội dung gần nhau, và điểm thấp nếu không liên quan. Nhờ đó, mô hình Diffusion học được ánh xạ rõ ràng hơn về việc một ảnh đầu vào nên được ánh xạ sang dạng nào ở đầu ra.
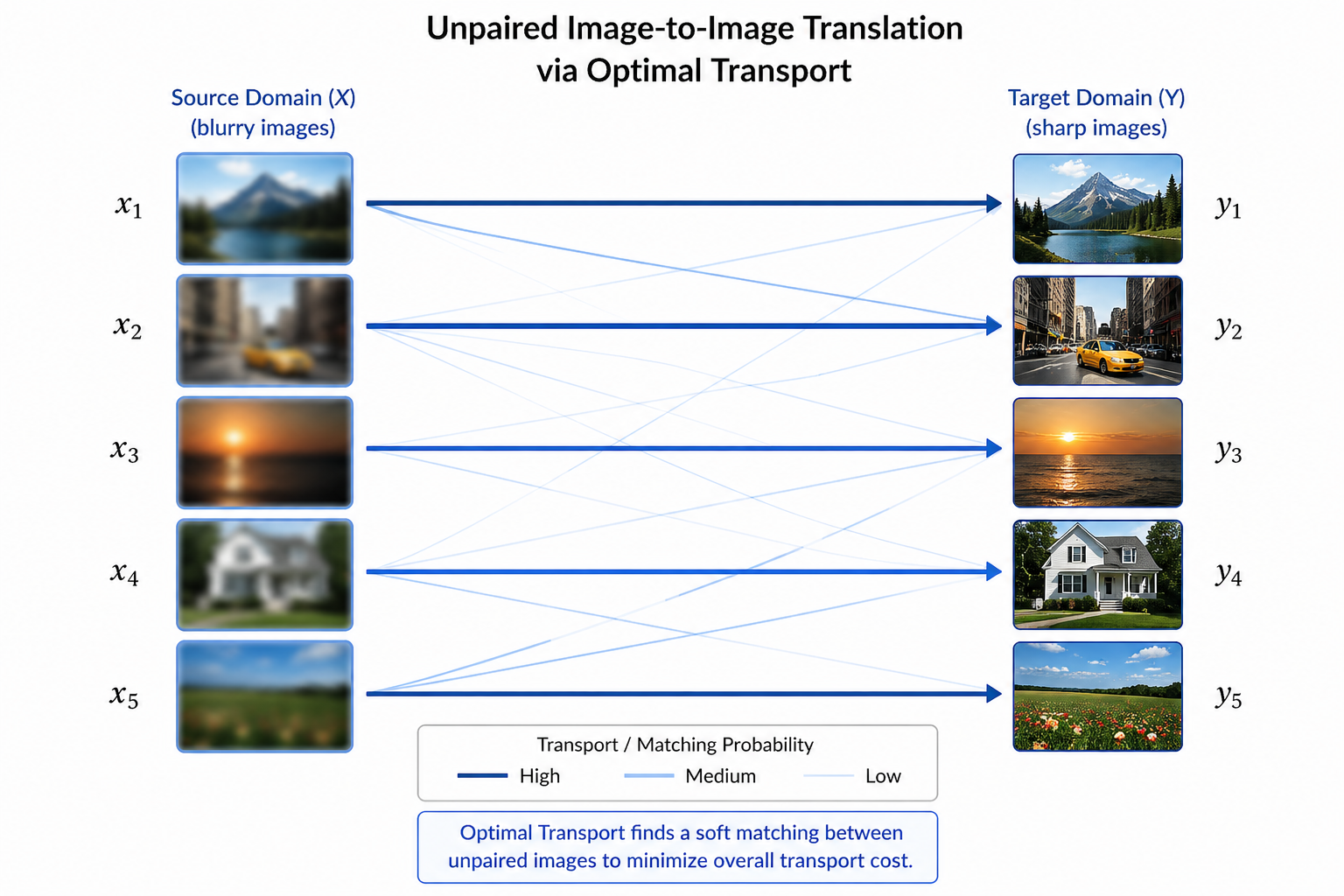
Optimal Transport thiết lập liên kết xác suất giữa hai tập dữ liệu không có cặp tương ứng, giúp mô hình học ánh xạ hợp lý hơn thay vì ghép nối ngẫu nhiên.
Bằng cách để OT làm kim chỉ nam, mô hình Diffusion trong OTCS tạo ra những bức ảnh cho kết quả tốt hơn trong các thí nghiệm được báo cáo theo các chỉ số độ chân thực (FID) và tính giữ nguyên cấu trúc (SSIM) so với việc chỉ dùng Diffusion thông thường hay các mô hình GAN trước đó.
5. Kết luận
Nhìn lại lịch sử từ những mô hình ngôn ngữ (LLMs) cổ điển đến sự bùng nổ của Transformers, chúng ta luôn thấy một xu hướng: Toán học càng phản ánh đúng bản chất của tự nhiên, mô hình càng mạnh mẽ.
Khái niệm về dòng chảy của xác suất không chỉ giới hạn ở việc sinh ra các bức ảnh đẹp. Trong một nghiên cứu, GS. Gabriel Peyré đã chỉ ra rằng quá trình huấn luyện một mạng Neural hay sự di chuyển của các token qua hàng chục lớp của một mô hình Transformer khổng lồ, về bản chất, cũng chính là những hạt xác suất đang trôi dạt theo các phương trình đạo hàm riêng (PDE) để tìm về trạng thái cực tiểu hóa năng lượng (Wasserstein Gradient Flows).
Từ sự hỗn loạn ngẫu nhiên của Diffusion, qua lăng kính gãy gọn của Flow Matching, cho đến sự tối ưu thanh lịch của Optimal Transport, các mô hình này có thể được hiểu như những cách khác nhau để mô hình hóa chuyển động của phân phối xác suất. Đó không chỉ là kỹ thuật, đó là nghệ thuật phơi lộ sự thật ẩn giấu trong những con số.
Và giống như chiếc lồng vô hình của thuật toán mà Heidegger từng cảnh báo, khi chúng ta càng hiểu rõ cách các dòng chảy này định hình dữ liệu, chúng ta càng phải có trách nhiệm trong việc định hướng chúng, không phải để vây bủa, mà để giải phóng sự sáng tạo vô tận của nhân loại.
Tài liệu đọc thêm
Related Articles
Discover more articles related to this topic

Fractal Dimension: Khi chiều không gian vượt thoát khỏi khuôn khổ số nguyên
Khám phá chiều fractal – một khái niệm đột phá trong hình học, vượt ra ngoài khuôn khổ số nguyên để mô tả sự phức tạp của tự nhiên. Bài viết đi sâu vào lịch sử, cơ sở toán học và vô vàn ứng dụng của fractal trong sinh học, vật lý, kinh tế và đặc biệt là khoa học máy tính và AI.

Ngôn Ngữ, Xác Suất và Nhận Thức – phương trình công nghệ trong lịch sử mô hình hóa ngôn ngữ của nhân loại
Khám phá hành trình tiến hóa vĩ đại của mô hình ngôn ngữ, nơi ngôn ngữ, xác suất và nhận thức đan xen trong suốt tiến trình lịch sử công nghệ: từ những mô hình thống kê N-gram giản đơn, đến mạng nơ-ron và RNN, rồi bứt phá với LSTM, Seq2Seq và Attention; từ cuộc cách mạng Transformer mở đường cho BERT, GPT và vô số biến thể, đến kỷ nguyên LLM với khả năng sáng tạo, suy luận, đa phương thức. Đây không chỉ là câu chuyện kỹ thuật, mà còn là bản trường ca triết học về cách máy móc phản chiếu tư duy con người và gợi mở viễn cảnh trí tuệ nhân tạo tổng quát.

MemVerse: Multimodal Memory và con đường hướng tới Lifelong Learning Agents
Phân tích MemVerse – một framework bộ nhớ đa phương thức cho AI Agents học tập suốt đời, kết hợp Knowledge Graph truy xuất và Parametric Memory để giải quyết bài toán catastrophic forgetting, tối ưu suy luận đa phương thức và tương tác dài hạn.

“Kỹ thuật là cách thế phơi lộ”: khi công nghệ định hình tự do của chúng ta
Heidegger từng nói kỹ thuật không chỉ là công cụ trong tay con người, mà là tấm gương định hình cách ta nhìn và sống trong thế giới. Ngày nay, khi trí tuệ nhân tạo bắt đầu can thiệp vào cách ta học hỏi, sáng tạo và ra quyết định, câu hỏi lớn vẫn vang vọng: liệu AI đang giúp chúng ta mở ra những lối đi mới, hay đang âm thầm dựng nên một chiếc lồng vô hình bủa vây tự do và suy tưởng của chính con người?
Discover all 6 articles in our blog